
Sheri Lederman is an experienced teacher in the Long Island district of Great Neck. This means that she, like every other teacher in the Empire State, has been subjected to an ongoing experiment of teacher evaluation roulette with increasing focus on the “value added” of individual teachers calculated using student standardized test scores plugged into complex statistical formulas. The method, called “Value Added Modeling,” is meant to account for the various factors that might impact a student’s score on a standardized test, isolate the teacher’s input on the student’s growth during one year of instruction, and determine whether or not the student learned as much as similarly situated students. The difference between what the VAM predicts and how the student does – for either better or worse – is used to determine whether or not an individual teacher is effective. VAMs promise to remove some of the subjectivity of teacher evaluation by relying solely upon tests that large numbers of students take and by calculating how well a teacher’s students did all things considered – literally. VAM formulas claim to account for differences in students’ socioeconomic backgrounds and home life and only hold teachers accountable for students’ predicted performance.
Sounds great. Trouble is that they don’t work.
The research base on VAMs continues to grow, but the evidence against them was strong enough that the American Statistical Association strongly cautioned against their use in individual and high stakes teacher evaluation in 2014. So, of course, New York took its already VAM heavy evaluation system and doubled down hard on the standardized testing component because Governor Andrew Cuomo decided that the evaluations were finding too many teachers competent. The previous system was, interestingly enough, the one that Ms. Lederman ran afoul of. According to this New York Times article, Ms. Lederman’s students performed very slightly lower on the English exam in the 2013-2014 school year than in the previous year, which was apparently enough to cause her test based effectiveness rating to plummet from 14 out of 20 points to 1 out of 20 points. While her overall evaluation was still positive, the VAM based portion of her evaluation still labeled Ms. Lederman as ineffective.
So she sued. In the court filing against then New York State Commissioner (and now U.S. Secretary of Education) John King, her argument was that the growth model used in New York “actually punishes excellence in education through a statistical black box which no rational educator or fact finder could see as fair, accurate or reliable.” In fact, we’ve seen this before when the growth model used by New York City determined that the absolute worst 8th grade math teacher in the entire city was a teacher at a citywide gifted and talented program whose students performed exceptionally on the statewide Regents Integrated Algebra Exam, a test mostly taken by tenth graders, but who did not perform as well as “predicted” on the state 8th grade mathematics test. It is important to remember that VAMs promise to explain the differences among student test scores by isolating the teacher’s effect on learning, but in order to do this, they have to mathematically peel away everything else. However, according to the American Statistical Association statement, most research suggests that teacher input counts for only 1-14% of the variation among student scores, so the VAMs have to literally carve away over 85% of the influences on how students do on standardized tests to work. No wonder, then, that the Lederman V. King filing called the models a “statistical black box” given that this is an example from New York City’s effort earlier in the decade:
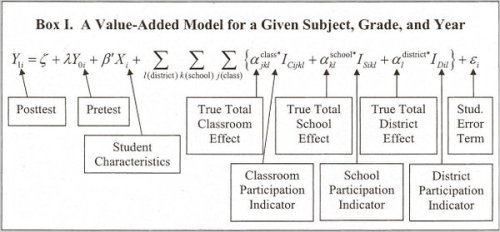
Not only are these models difficult to impossible for teachers and most administrators to understand, they simply do not perform as advertised. Schochet and Chiang, in a 2010 report for Mathematica, found that in trying to classify teachers via growth models, error rates as high as 26% were possible when using three years of data, meaning one in four teachers could easily be misclassified in any given evaluation even if the evaluation used multiple years of data. Dr. Bruce Baker of Rutgers wanted to test the often floated talking point that some teachers are “irreplaceable” because they demonstrate a very high value added using student test scores. What he found, using New York City data, was an unstable mess where teachers were much more likely to ping around from the top 20% to below that and back up again over a five year stretch. So as a tool for providing evaluators with clear and helpful information on teachers’ effectiveness, it would perhaps be better to represent that VAM formula like this:
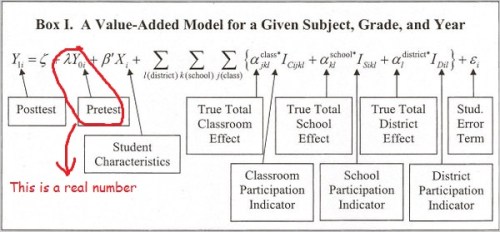
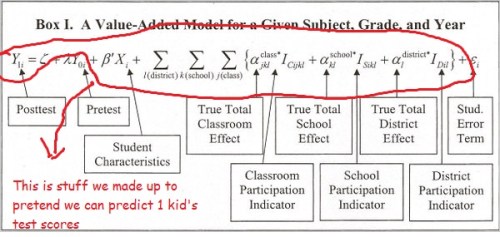
The judge in Ms. Lederman’s case ruled this week, and, as the linked news articles stated, he vacated her evaluation, saying that it had been “arbitrary and capricious.” The judge’s ruling is, by necessity, limited in scope because the evaluation system that gave Ms. Lederman her low value added rating no longer exists, having been replaced by Governor Andrew Cuomo’s 2015 push to tie HALF of teacher evaluations to test scores and then by the New York State Education Department’s somewhat frenzied efforts to implement that which has resulted in a temporary bar on using the state tests for those evaluations. The ruling is still significant because the judge recognized the deep, and likely unsolvable, problems with the VAM system used in the Lederman case. According to Dr. Audrey Armein-Beardsley, the judge acknowledged:
(1) the convincing and detailed evidence of VAM bias against teachers at both ends of the spectrum (e.g. those with high-performing students or those with low-performing students); (2) the disproportionate effect of petitioner’s small class size and relatively large percentage of high-performing students; (3) the functional inability of high-performing students to demonstrate growth akin to lower-performing students; (4) the wholly unexplained swing in petitioner’s growth score from 14 [i.e., her growth score the year prior] to 1, despite the presence of statistically similar scoring students in her respective classes; and, most tellingly, (5) the strict imposition of rating constraints in the form of a “bell curve” that places teachers in four categories via pre-determined percentages regardless of whether the performance of students dramatically rose or dramatically fell from the previous year.”
Equally important as the court’s recognition of arguments against value-added models in teacher evaluation, is the ground that was broken with the ruling. Ms. Lederman’s attorney (and husband), Bruce Lederman, sent out a message reported by New York City education activist Leonie Haimson which said, in part, ” …To my knowledge, this is the first time a judge has set aside an individual teacher’s VAM rating based upon a presentation like we made.” The significance of this cannot be overstated. For years now, teachers have been on the defensive and largely powerless, subjected to poorly thought out policies which, nevertheless, had force of policy and law on their side. Lederman v. King begins the process of flipping that script, giving New York teachers an effective argument to make on their behalf and challenging policy makers to find some means of defending their desire to use evaluation tools that are “capricious and arbitrary.” While this case will not overturn whatever system NYSED thinks up next, it should force Albany to think really long and hard about how many times they want to defend themselves in court from wave after wave of teachers challenging their test-based ratings.

Reblogged this on David R. Taylor-Thoughts on Education.
A very detailed understanding here, and much appreciated. I personally know that any type of VAM legislation will simply undermine education because that is exactly what has happened in our district: we have little left but chaos. In an honest look at the idea of using VAM scores for “all” teachers, we can see that this simply allows those in charge to blame and remove expensive career educators and replace them with short-term (no-pension) greenhorns. School reform thus turns into nothing but smoke and mirrors.
That VAM formula graphic should go viral! Thank you for your insightful remarks, as always.
Daniel, thank you for your insightful analysis of the issues educators are all still facing. My win in court is just the first step in the effort to absolve ourselves of an arbitrary and capricious system of “evaluation”.
Sheri Lederman, Ed.D.
My pleasure, Dr. Lederman, and thank YOU for helping this important step to move ahead! I am sure many more teachers will be thanking you!
Bless you both!
Thanks for going “old school,” Dr. Lederman, and showing these bullies some good old fashioned NY GRIT!
Pingback: Daniel Katz on the Meaning of Sheri Lederman’s Victory in Court Against VAM | Diane Ravitch's blog
Reblogged this on ACADEME BLOG and commented:
This piece by Seton Hall professor Daniel Katz provides a thorough and devastating take on the bogus teacher evaluation program dismissed as “arbitrary and capricious” by a New Youk court, about which I blogged yesterday (https://academeblog.org/2016/05/12/an-important-decision-on-teacher-evaluation/)
Pingback: The Albatross | undercoverBAT's Blog